개요
현재 Fitsme 에서 리뷰 분석을 하는데 AutoML 이 너무 비싸다. 그래서 Text Classification 을 직접 구현해보려고 한다.
목적
현재 glowpick 의 리뷰들에서 마무리감 및 커버력을 텍스트 분석을 통해서 multi classification 을 해서 도출해낼 수 있도록 하는것!
기대 동작 및 효과
텍스트 원문을 그대로 넣었을 때 문장을 분석해서 마무리감 및 커버력 (두꺼운 정도)을 classification 할 수 있도록 하는 것.
어떻게 할 수 있나? 2 가지 질문에 대한 답!!!
1.
텍스트(원본 데이터)와 라벨의 관계를 학습시키기 위해서 어떻게 효과적으로 데이터를 전처리 해야할까
2.
어떤 학습 알고리즘과 모델을 사용해야 할까
data pre-processing
•
데이터 (samples) 들 중에서 일반적으로는 80%는 학습 데이터, 20%는 유효성 검사를 위해서 사용됨 (절대적이지는 않음)
•
이를 위해서 sample 들의 무작위성이 보장되는 것이 좋다. (특정 군만 테스트에 포함된다거나 하는 경우가 worst)
Text pre-processing

모델에게 학습을 시키기 전에 데이터들을 모델이 이해할 수 있도록 변경해야한다!
ML 에서 학습 알고리즘들은 input 으로 number 값들을 받는다. 때문에 text 데이터를 numberical vactors 로 변환해야한다. 여기에는 다음 두 가지 단계가 있다.
•
Tokenization
텍스트를 label 사이의 관계를 잘 일반화 할 수 있는 단어, 혹은 작은 텍스트로 변경하는 작업이다. 데이터 세트 (데이터에 존재하는 고유 한 토큰 세트)의 "단어들"을 결정합니다.
토큰의 기준을 단어(word)로 하는 경우, 단어 토큰화(word tokenization)라고 합니다. 다만, 여기서 단어(word)는 단어 단위 외에도 단어구, 의미를 갖는 문자열로도 간주되기도 합니다.
예를 들어보겠습니다. 아래의 입력으로부터 구두점(punctuation)과 같은 문자는 제외시키는 간단한 단어 토큰화 작업을 해봅시다. 구두점이란, 온점(.), 컴마(,), 물음표(?), 세미콜론(;), 느낌표(!) 등과 같은 기호를 말합니다.
입력: Time is an illusion. Lunchtime double so!
이러한 입력으로부터 구두점을 제외시킨 토큰화 작업의 결과는 다음과 같습니다.
출력 : "Time", "is", "an", "illustion", "Lunchtime", "double", "so"
이 예제에서 토큰화 작업은 굉장히 간단합니다. 구두점을 지운 뒤에 띄어쓰기(whitespace)를 기준으로 잘라냈습니다. 하지만 이 예제는 토큰화의 가장 기초적인 예제를 보여준 것에 불과합니다.
보통 토큰화 작업은 단순히 구두점이나 특수문자를 전부 제거하는 정제(cleaning) 작업을 수행하는 것만으로 해결되지 않습니다. 구두점이나 특수문자를 전부 제거하면 토큰이 의미를 잃어버리는 경우가 발생하기도 합니다. 심지어 띄어쓰기 단위로 자르면 사실상 단어 토큰이 구분되는 영어와 달리, 한국어는 띄어쓰기만으로는 단어 토큰을 구분하기 어렵습니다. 그 이유는 여기에 정리했습니다.
크게 단어 토큰화와 문장 토큰화가 있다.
토큰화에서 고려할 점
◦
구두점이나 특수 문자를 단순 제외해서는 안 된다.
▪
문장의 경계를 알 수 있다
▪
단어 자체에 특수, 구두점을 가지고 있을 수 있다
◦
줄임말, 단어 내 띄어쓰기
•
Vectorization
Tokenization 된 텍스트들을 특성화하기 위해 적절한 수치 측정을 정의한다
한국어는 토큰화
한국어 형태소 분석은 KoNLPy 를 사용하면 될 것
•
영어와 달리 띄어쓰기만으로 토큰화를 하기엔 부족하다. 심지어 영어에 비해서 띄어쓰기가 잘 지켜지지 않는다
◦
한국어는 어절 단위로 띄어쓰기가 됨.
◦
어절 토큰화는 한국어 NLP 에서 지양됨 ⇒ 단어 토큰화와 다르기 때문
•
때문에 한국어 토큰화에서는 형태소 분석이 필수! 형태소는 크게 두 가지가 존재
◦
자립 형태소 - 접사, 어미 등과 관계 없이 그 자체로 사용 가능
◦
의존 형태소 - 다른 형태소와 결합되어 사용되는 형태소
품사 태깅
단어 표기는 같지만 품사에 따라서 단어의 의미가 다른 경우가 있다 (ex - 못을 박다, 못 먹는다)
때문에 토큰화 과정에서 어떤 품사로 사용 되었는지 구분하기도 하는데 위 작업을 품사태깅이라고 한다.
Tokenization
결국 한국어를 토큰화 할 때, 단어 토큰이 아니라 형태소 토큰을 사용할 수도 있다! (아니면 필요한 형태소만 따로 filter 해서 사용할 수도 있겠다.
N-gram vectors
n-gram vector 에서 텍스트는 유니크한 n-gram(인접한 토큰(주로 단어들)의 그룹)들로 표현된다. 예를 들어서 The mouse ran up the clock 이란 문자가 있다면 ['the', 'mouse', 'ran', 'up', 'clock'](n = 1. unigram) / ['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] (n = 2. bigram) 등으로 표현될 수 있는 것이다.
tokenization
단어들을 unigram or bigrams 로 토큰화 하면 적은 컴퓨팅 파워로 효과적인 정확성을 얻을 수 있다.
vectorization
n-gram tokenization 에서 토큰화 했던 토큰들을 numerical vector 로 변환한다.
// example
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10,
'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the
clock': 8, 'down': 1, 'ran down': 5}
JavaScript
복사
Indexes 를 할당하고 난 후 vectorize 를 할 때 선택할 수 있는 옵션들이 있다.
One-hot encoding
모든 샘플 텍스트는 텍스트에 토큰의 존재 여부를 나타내는 벡터로 표시됨
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
JavaScript
복사
Count encoding
모든 샘플 텍스트는 텍스트의 토큰 수를 나타내는 벡터로 표시됨
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
JavaScript
복사
Tf-idf encoding
위의 두 모델에서는 흔히 쓰이는 (label 을 결정짓는 워딩과 전혀 관계 없는) 관용어구들에 대한 페널티가 없다(예로 the 등). 위의 예에서 the 가 많아봤자 그다지 유용하지 않은 결과가 나올 것.
TF-IDF(Term Frequency-Inverse Document Frequency)는 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내의 각 단어들마다 중요한 정도를 가중치로 주는 방법
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33,
0.23, 0.33, 0.33]
JavaScript
복사
많은 옵션이 있지만 일반적으로 위의 세 개가 사용된다. 그리고 일반적으로 TF_IDF 인코딩이 n-gram 에서는 정확성을 더 높여줄 것이다 (대신 메모리 점유, 컴퓨팅 파워가 더필요, 시간이 더 걸림. 데이터 셋이 크면 클 수록 두드러질 것)
Feature selection
텍스트를 tokenization 을 하고 나면 수만가지의 토콘이 생길 수도 있다. 그러나 이러한 모든 토큰들이 label 을 예측하는데 도움이 되지는 않는다. 그래서 아주 드물게 나타나거나 하는 등의 토큰들은 빼버릴 수 있다. 그리고 feature 들에 대해서 label 예측에 얼마나 기여하는지 측정도 할 수 있고, 유익한 토큰들만 포함시킬 수도 있다.
위 함수들을 통해서 Top n 개의 feature(token)들만 포함 시켜서 수행 시키는 것이 좋다. features 가 많으면 모든 과정에서 computing 파워를 많이쓰고, 시간이 많이 걸릴 뿐만 아니라. overfitting 이 발생할 수도 있고, 오히려 정확성을 저하시킬 수 있다.
Normalization
정규화는 변환된 vector 값들을 더 작은 (그러나 유효한) 값으로 변환한다. 이를 통해서 학습에서 경사 하강 수렴이 단순화된다. (생략 해도 되는 과정. 그런데 best practice 이긴 함. 다만 classification 에서도 필요한가에 대한 의문....)
한줄 요약 = bag-of-words approach
Sequence Vectors
몇몇의 텍스트 샘플에서는 단어의 순서가 의미를 나타내는데 핵심이 되기도 한다. CNNs / RNNs 와 같은 모델들은 단어들의 순서에 의한 의미를 학습하도록 할 수 있다. 이러한 모델들의 경우, 텍스트 순서를 유지하면서 토큰으로 나타낸다
tokenization
철자의 순서 및 단어들의 순서로 표현될 수 있다. 일반적으로 단어들의 순서로 tokenization 된다.
vetorization
exts: 'The mouse ran up the clock' and 'The mouse ran down'
Index assigned for every token: {'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}.
JavaScript
복사
sequence token 을 생성하기 위한 두 가지 옵션
One-hot encoding
n차원 vector 을 통해서 표현이 가능하다. n 은 단어의 갯수다.
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
JavaScript
복사
음. 매우 비효율적이다
Word embeddings
단어들은 그 자체로 의미를 담고 있다. 단어들 간에 의미적으로 얼마나 유사한지 위치와 거리가 표현 가능하다. 이것을 word embedding 이라고 한다.
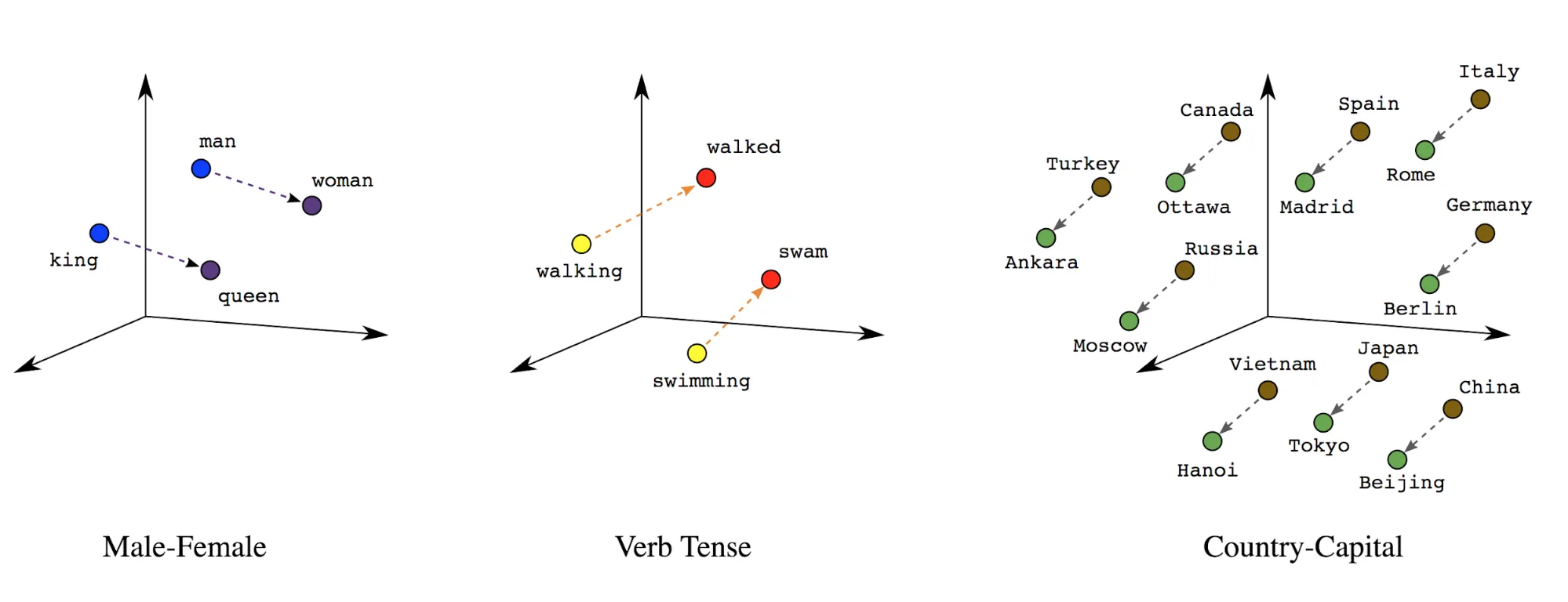
우선 텍스트를 first layer 에서 index 시퀀스를 단어를 포함하는 벡터로 변환한다. 그 후 각 단어의 index 가 의미 공간(위 그림 참조)에서 어떤 위치를 가지는지에 대한 실제 값을 dense layer 에서 표시되도록 한다.
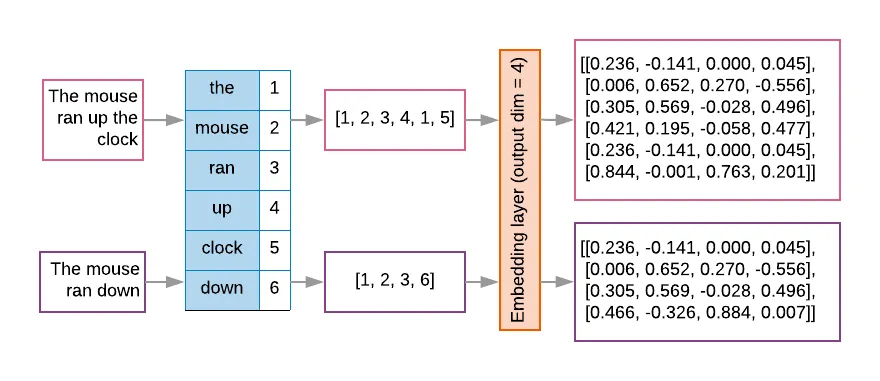
Label vectorization
위와 마찬가지로 label 들에 대해서도 numerical vector 화 해야한다. 단순하게 [0, num_classes - 1] 의 형태로 변환하는 것도 가능하다. 만약에 3개의 class 가 있다면, 0, 1, 2 를 사용하면 되는 것이다!
Flow Decision chart (from google)
아래의 그림은 첫 실험에 대해서 설계를 할 때 설계의 구조를 잡는데 도움이 될 것.
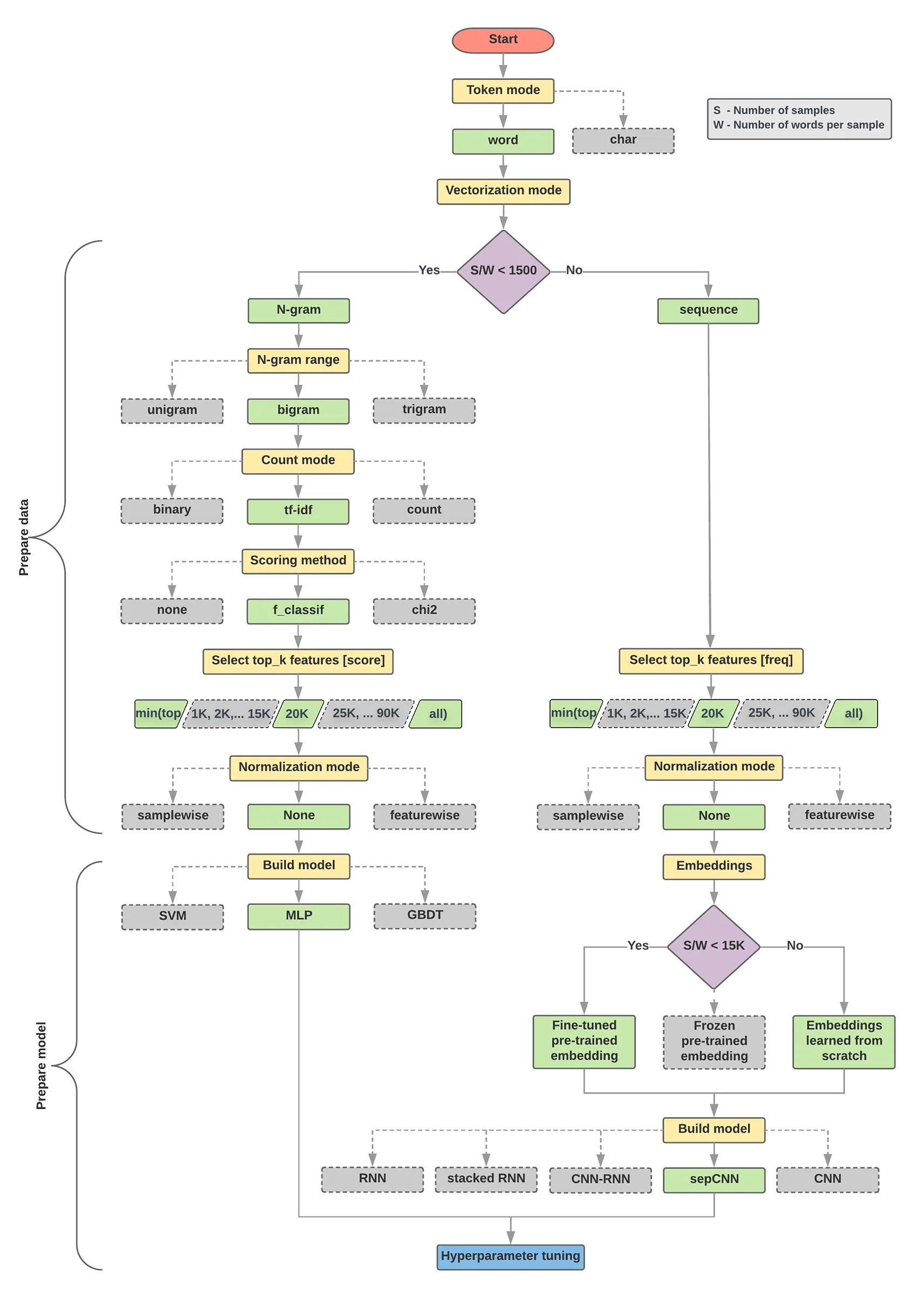
data pre-processing algorythm
1.
샘플 비율 당 샘플 수 / 단어 수를 계산합니다.
2.
2.이 비율이 1500 미만인 경우 텍스트를 n- 그램으로 토큰 화하고 간단한 MLP (Multi-Layer Perceptron) 모델을 사용하여 분류합니다 (아래 순서도의 왼쪽 분기). 샘플을 워드 n- 그램으로 분할, n- 그램을 벡터로 변환합니다. 벡터의 중요성을 평가 한 다음 점수를 사용하여 상위 20K를 선택합니다
3.
비율이 1500보다 크면 텍스트를 시퀀스로 토큰 화하고 sepCNN 모델을 사용하여 분류합니다 (아래 순서도의 오른쪽 분기). 샘플을 단어로 나눕니다. 빈도에 따라 상위 20K 단어를 선택하십시오. 비. 샘플을 단어 시퀀스 벡터로 변환합니다. 씨. 원래 샘플 수 / 샘플 비율 당 단어 수가 15K 미만인 경우 sepCNN 모델에 미리 조정 된 사전 훈련 된 임베딩을 사용하면 최상의 결과를 얻을 수 있습니다.
4.
다른 하이퍼 파라미터 값으로 모델 성능을 측정하여 데이터 세트에 가장 적합한 모델 구성을 찾으십시오.
모델 선택
before read!! - 절대적인 것은 아니다. 보편적으로 정확성을 높이고, computing 파워를 덜 쓸 수 있는 방법에 대해서 기술한 것이지, 모든 요소에 적합하다고 할 수는 없다. ML 을 하는 목적이 모두 다르고,
모델은 크게 두 가지의 카테고리로 선택할 수 있다.
1.
단어의 순서에 의한 정보 (Sequence model)
a.
convolutional neural networks(CNNs)
b.
recurrent neural networks (RNNs)
2.
텍스트를 단어들의 모음으로 생각해서 정보를 얻는 모델 (N-gram model)
a.
logistic regression
b.
simple multi- layer perceptrons
c.
gradient boosted trees
d.
support vector machines.
모델 선택의 기준은 어떻게 되어야할까?
From our experiments, we have observed that the ratio of “number of samples” (S) to “number of words per sample” (W) correlates with which model performs well.
만약 S/W 의 비율이 1500 이하일 때, n-gram 의 형식을 취하는 multi- layer perceptrons(MLP)가 최소한 sequence model 보다 작업을 잘 수행할 것이다. MLP 는 간단하게 정의하고 이해할 수 있고, sequence model 보다 컴퓨팅 파워도 덜 쓴다.
만약 S/W 의 비율이 1500 가 넘을 때, sequence model 을 사용한다.
구성
Tensorflow 로 해야지....
참고 - 리뷰 분석 (긍정 부정 2진 분석)
참고2 - 텍스트 classification 모델 분류 선택 방법