
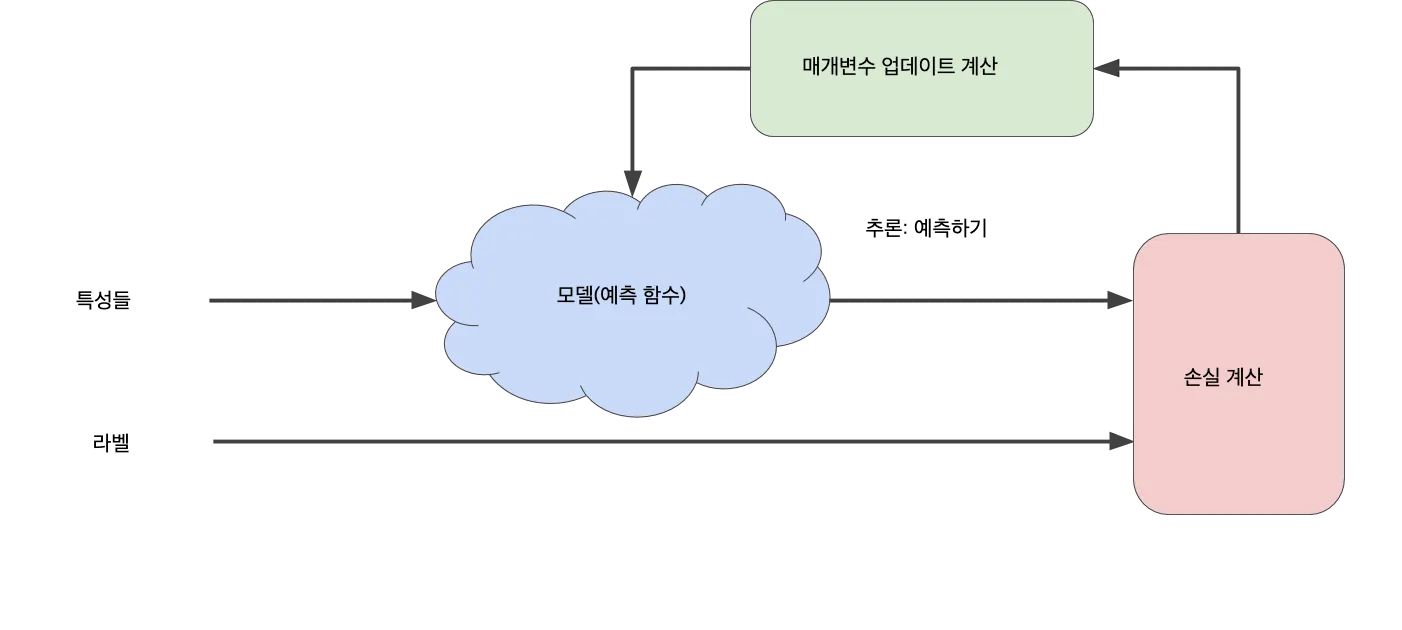
위의 다이어그램에서 '손실 계산' 과정은 이 모델에서 사용할 손실 함수입니다
경사하강법
1.
경사하강법의 첫 번째 단계는 에 대한 시작 값(시작점)을 선택하는 것입니다. 시작점은 별로 중요하지 않습니다. 따라서 많은 알고리즘에서는 을 0으로 설정하거나 임의의 값을 선택합니다
2.
그런 다음 경사하강법 알고리즘은 시작점에서 손실 곡선의 기울기를 계산합니다. 간단히 설명하자면 기울기는 편미분의 벡터로서, 어느 방향이 '더 정확한지' 혹은 '더 부정확한지' 알려줍니다.
학습률 (or 보폭)
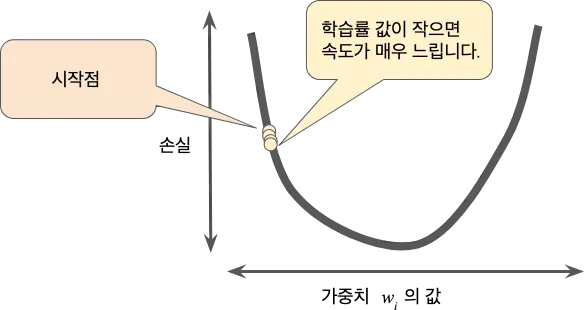
경사하강법 알고리즘은 기울기에 합습률이라 불리는 스칼라를 곱하여 다음 지점을 결정합니다. 학습률을 너무 작게 설정하면 학습 시간이 매우 오래 걸릴 것입니다
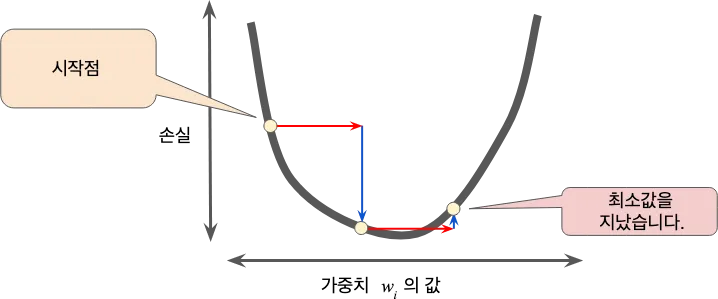
반대로 학습률을 너무 크게 설정하면 양자역학 실험을 잘못한 것처럼 다음 지점이 곡선의 최저점을 무질서하게 이탈할 우려가 있습니다.
골디락스 학습률
모든 회귀 문제에는 골디락스 학습률이 있습니다. 골디락스 값은 손실 함수가 얼마나 평탄한지 여부와 관련 있습니다. 손실 함수의 기울기가 작다면 더 큰 학습률을 시도해 볼 수 있습니다. 이렇게 하면 작은 기울기를 보완하고 더 큰 보폭을 만들어 낼 수 있습니다.
손실 줄이기: 확률적 경사하강법
경사하강법에서 배치는 단일 반복에서 기울기를 계산하는 데 사용하는 예의 총 개수입니다. 데이터 세트가 클 수록 배치가 거대해질 수 있습니다. 다만 배치가 너무 커지면 단일 반복으로도 계산하는 데 오랜 시간이 걸릴 수 있습니다.
무작위로 샘플링된 예가 포함된 대량의 데이터 세트에는 중복 데이터가 포함되어 있을 수 있습니다. 실제로 배치 크기가 커지면 중복의 가능성도 그만큼 높아집니다. 적당한 중복성은 노이즈가 있는 기울기를 평활화하는 데 유용할 수 있지만, 배치가 거대해지면 예측성이 훨씬 높은 값이 대용량 배치에 비해 덜 포함되는 경향이 있습니다.
만약에 훨씬 적은 계산으로 적절한 기울기를 얻을 수 있다면 어떨까요? 데이터 세트에서 예를 무작위로 선택하면 (노이즈는 있겠지만) 훨씬 적은 데이터 세트로 중요한 평균값을 추정할 수 있습니다. 확률적 경사하강법(SGD)은 이 아이디어를 더욱 확장한 것으로서, 반복당 하나의 예(배치 크기 1)만을 사용합니다. 반복이 충분하면 SGD가 효과는 있지만 노이즈가 매우 심합니다. '확률적(Stochastic)'이라는 용어는 각 배치를 포함하는 하나의 예가 무작위로 선택된다는 것을 나타냅니다.
미니 배치 확률적 경사하강법(미니 배치 SGD)는 전체 배치 반복과 SGD 간의 절충안입니다. 미니 배치는 일반적으로 무작위로 선택한 10개에서 1,000개 사이의 예로 구성됩니다. 미니 배치 SGD는 SGD의 노이즈를 줄이면서도 전체 배치보다는 더 효율적입니다.
용어
경사하강법(gradient descent)
매개변수(parameter)
ML 시스템에서 스스로 학습하는 모델의 변수입니다. 예를 들어 ML 시스템에서 학습이 반복됨에 따라 가중치 매개변수의 값이 서서히 학습됩니다.
초매개변수(hyperparameter)
모델 학습을 연속적으로 실행하는 중에 사용자 본인 에 의해 조작되는 '손잡이'입니다. 예를 들어 학습률은 초매개변수 중 하나입니다.
매개변수와 대비되는 개념입니다.
학습률(learning rate)
경사하강법을 통해 모델을 학습시키는 데 사용되는 스칼라값입니다. 각 반복에서 경사하강법 알고리즘은 학습률을 경사에 곱합니다. 이 곱셈의 결과를 경사 스텝이라고 합니다
배치(batch)
모델 학습의 반복 1회, 즉 경사 업데이트 1회에 사용되는 예의 집합. 배치 크기는 배치 하나에 포함되는 예의 개수.
확률적 경사하강법(SGD, stochastic gradient descent)
배치 크기가 1인 경사하강법 알고리즘입니다. 즉, 확률적 경사하강법은 데이터 세트에서 무작위로 균일하게 선택한 하나의 예에 의존하여 각 단계의 예측 경사를 계산합니다.
미니 배치(mini-batch)
학습 또는 추론의 단일 반복에서 함께 실행되는 예의 전체 배치 중에서 무작위로 선택한 소규모 부분 집합입니다. 미니 배치의 배치 크기는 일반적으로 10~1,000입니다. 전체 학습 데이터가 아닌 미니 배치의 손실을 계산하면 효율성이 크게 향상됩니다.